GPT-3
GPT-3 is an enormous model built on the transformer-decoder architecture published in 2020 by OpenAI in this paper: “Language Models are Few-Shot Learners” whose title is very indicative of what the paper wanted to show. The paper didn’t provide any new architecture, they used the same architecture as GPT-2. They just made it way bigger and trained over more data.
The whole purpose of this paper is to show that GPT-3 can be used with a variety of tasks using either zero-shot, or one-shot or a few-shots learning schemes and even reaching competitiveness with prior state-of-the-art fine-tuned models. Before getting into more details about the model, let’s first discuss what do I mean by these learning schemes and how they are different from fine-tuning:
- Few-shot (FS):
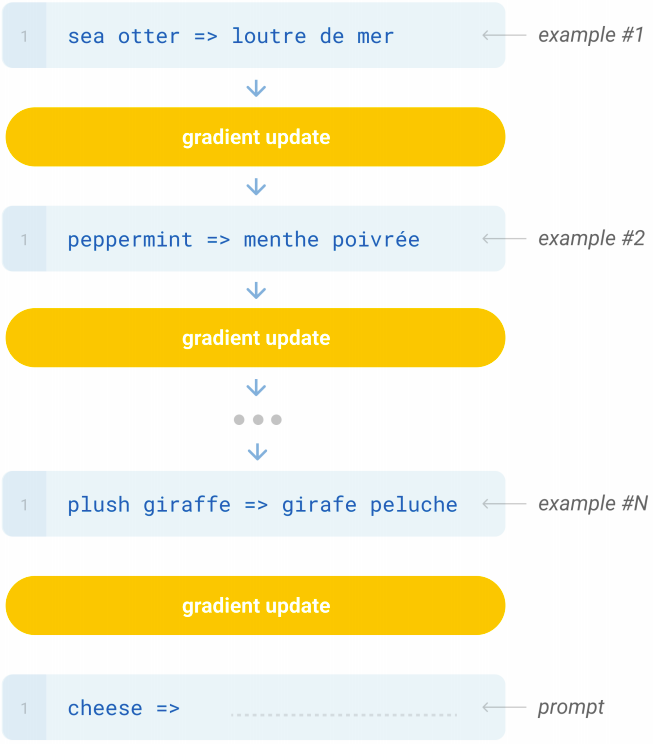
It’s the setting where the model is given K (usually from 10 to 100) examples of the task at inference time as conditioning, but no weight updates are allowed. As we can see in the following figure, GPT-3 was given three different examples along with the task description:

- One-shot (1S):
It’s the same as few-shot except that only one demonstration is allowed, in addition to the task description. The reason to distinguish one-shot from few-shot is that it most closely matches the way in which some tasks are communicated to humans:

- Zero-shot (0S):
It’s the same as one-shot except that no demonstrations are allowed, just the task description. This method provides maximum potential for robustness but is also the most challenging setting even for humans.

- Fine-Tuning (FT):
It has been the most common approach in recent years, and involves updating the weights of a pre-trained model by training on a supervised dataset specific to the desired task. This setting lacks from poor generalization out-of-distribution:
Model
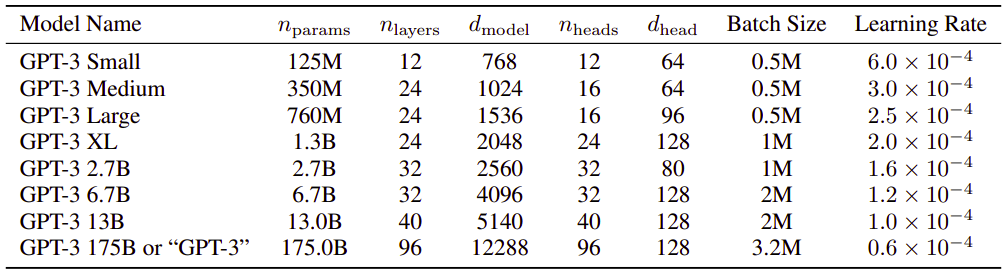
As said earlier, they used the same model and architecture as GPT-2. To study the dependence of performance on model size, they trained 8 different sizes of model as shown in the following table
Where:
-
$n_{\text{params}}$: is the total number of trainable parameters.
-
$n_{\text{layers}}$: is the total number of layers.
-
$d_{\text{model}}$: is the number of units in each bottleneck layer (we always have the feed-forward layer four times the size of the bottleneck layer, $d_{\text{feedforward}} = 4 \times d_{\text{model}}$).
-
$n_{\text{heads}}$: is the number of attention heads/layers, since each layer has just one attention head.
-
$d_{head}$: is the dimension of each attention head.
As you can see, GPT3 is massive as its context-widow $n_{\text{ctx}} = 2048$ tokens wide with about 175 billion learnable parameters spread over 96 transformer-decoder layers.
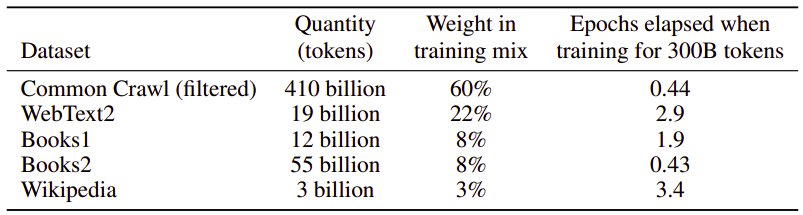
The data used for this models are according to the following table
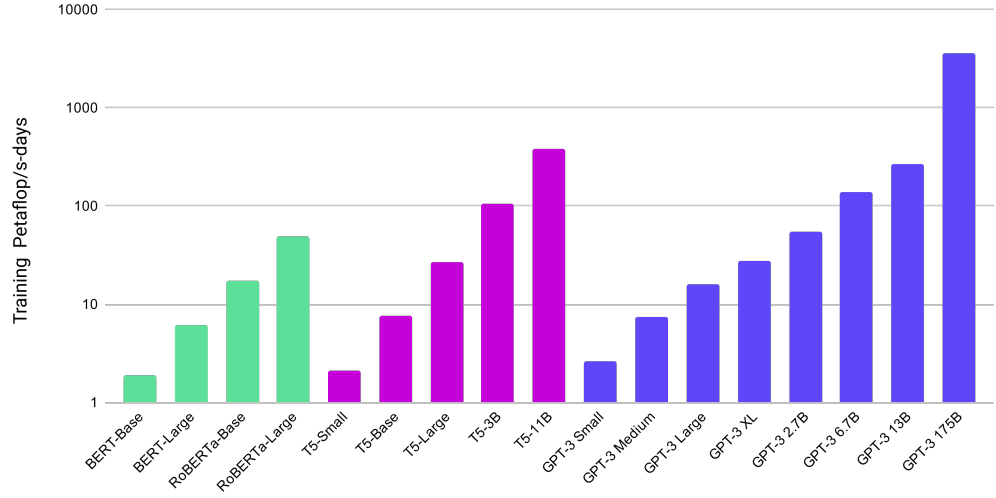
And the following is a comparison between the training time taken to train BERT, RoBERTa, T5 and GPT-3. As we can see from the graph, it took almost 5000 days to train GPT-3.
Results
The following is a comparison among the different learning schemes used with GPT-3 and the state or the art (fine-tuned) model on various tasks:
-
Language Modeling:
-
Dataset: Penn Tree Bank
-
Evaluation Metric: perplexity
-

-
Long-Range Language Modeling:
-
Dataset: LAMBADA
-
Evaluation Metric: perplexity / Accuracy
-

-
Story Completion:
-
Dataset: StoryCloze & HellaSwag
-
Evaluation Metric: Accuracy
-

-
Question Answering:
-
Dataset: NaturalQS, WebQS & TriviaQA
-
Evaluation Metric: Accuracy
-

-
Machine Translation:
-
Dataset: WMT’14 (Fr↔En), WMT’16 (De↔En) & WMT’16 (Ro↔En).
-
Evaluation Metric: BLEU
-
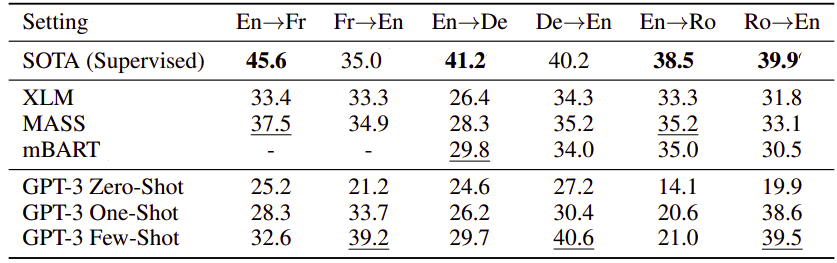
-
Winograd-Style Tasks: determining to which word a pronoun refers
-
Dataset: Winograd & WinogradXL
-
Evaluation Metric: Accuracy
-
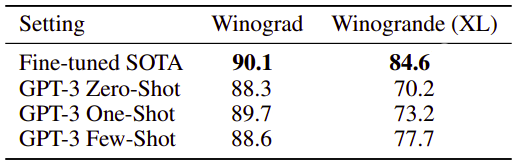
-
Common Sense Reasoning:
-
Dataset: PIQA, ARC, OpenBookQA
-
Evaluation Metric: Accuracy
-

-
Reading Comprehension:
-
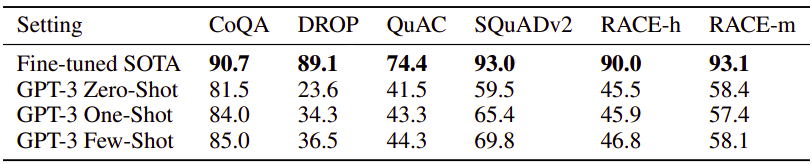
Dataset: CoQA, DROP, QuAC, SQuADv2, RACE-h, RACE-m.
-
Evaluation Metric: Accuracy for RACE-h & RACE-m, and F1 for the rest.
-