UNdreaMT
The first model proposed in this area was created under the supervision of Cho in 2017 and published in this paper: “Unsupervised Neural Machine Translation”. The official code of this paper can be found in the following GitHub repository: UNdreaMT. The proposed system follows a standard encoder-decoder architecture with an attention mechanism where:
-
There is one encoder which is a two-layer bidirectional RNN
-
There are two decoders, each is a two-layer RNN.
-
All RNNs use GRU cells with 600 hidden units, and the dimensionality of the embeddings is set to 300.
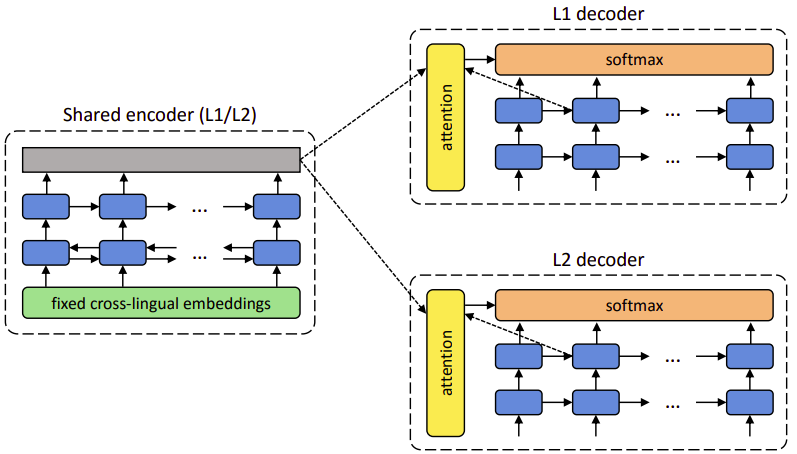
There are, however, three important aspects in which the system differs from the standard encoder-decoder NMT:
-
Dual structure:
While NMT systems are typically built for a specific translation direction (A→B). Here, the model exploited the dual nature of machine translation and handle both directions at the same time (A→B) and (B→A). Hence the usage of two decoders. -
Shared encoder:
The system makes use of only one encoder that is shared by both languages involved. This universal encoder is aimed to produce a language independent representation of the input text, which each decoder should then transform into its corresponding language. -
Fixed Cross-lingual embeddings at encoder:
While most NMT systems randomly initialize their embeddings and update them during training, they used pre-trained cross-lingual embeddings in the encoder that are kept fixed during training.
This NMT system is trained in unsupervised using the following two strategies:
-
Denoising.
-
On-the-fly back-translation
During training, we alternate between the two languages. Given two languages L1 and L2, each iteration would perform one mini-batch of denoising for L1, another one for L2, one mini-batch of on-the-fly back-translation from L1 to L2, and another one from L2 to L1.
Denoising
The whole idea of the system is to train a model to reconstruct its own input. More concretely, the system takes an input sentence in a given language, encode it using the shared encoder, and reconstruct the original sentence using the decoder of that language. That’s why we have two decoders for each language.
But this training procedure is essentially a trivial copying task. And it’s highly probable that our model could just blindly copy elements from the input sequence without gaining any real knowledge. In order to avoid that, they used denoising. Denoising is the process of applying a noise function on the input. The noise function they used is “swapping”. For a sequence of N elements, they made N/2 random swaps of this kind.
This way, the system needs to learn about the internal structure of the languages involved to be able to recover the correct word order. At the same time, by discouraging the system to rely too much on the word order of the input sequence.
On-the-fly Back-translation
So far, the model only uses monolingual data. In order to train our system in a true translation setting without violating the constraint of using nothing but monolingual corpora, they adapted the back-translation approach proposed to the model.
More concretely, given an input sentence in one language, the system is used in inference mode with greedy decoding to translate the input to the other language. This way, we obtain a pseudo-parallel sentence pair, and train the system to predict the original sentence from this synthetic translation.
Note that, contrary to standard back-translation, which uses an independent model to back-translate the entire corpus at one time, the model takes advantage of the dual structure of the proposed architecture to back-translate each mini-batch on-the-fly. Hence, the name “on-the-fly back-translation”.
Results
TO BE CONTINUED...